AWS Lambda のエラー通知を際に考慮した方が良さそうな点
はじめに
AWS Lambda を利用してAPIサーバやバッチシステム等を構成している際、 エラー通知等をSlackに送信したいとなった場合、いろいろな構成が考えられるかと思いますが、私が採用した構成でいくつか考慮した点があったためそのあたりを記録として残しておきたいと思います。
以下、今回採用した構成になります。
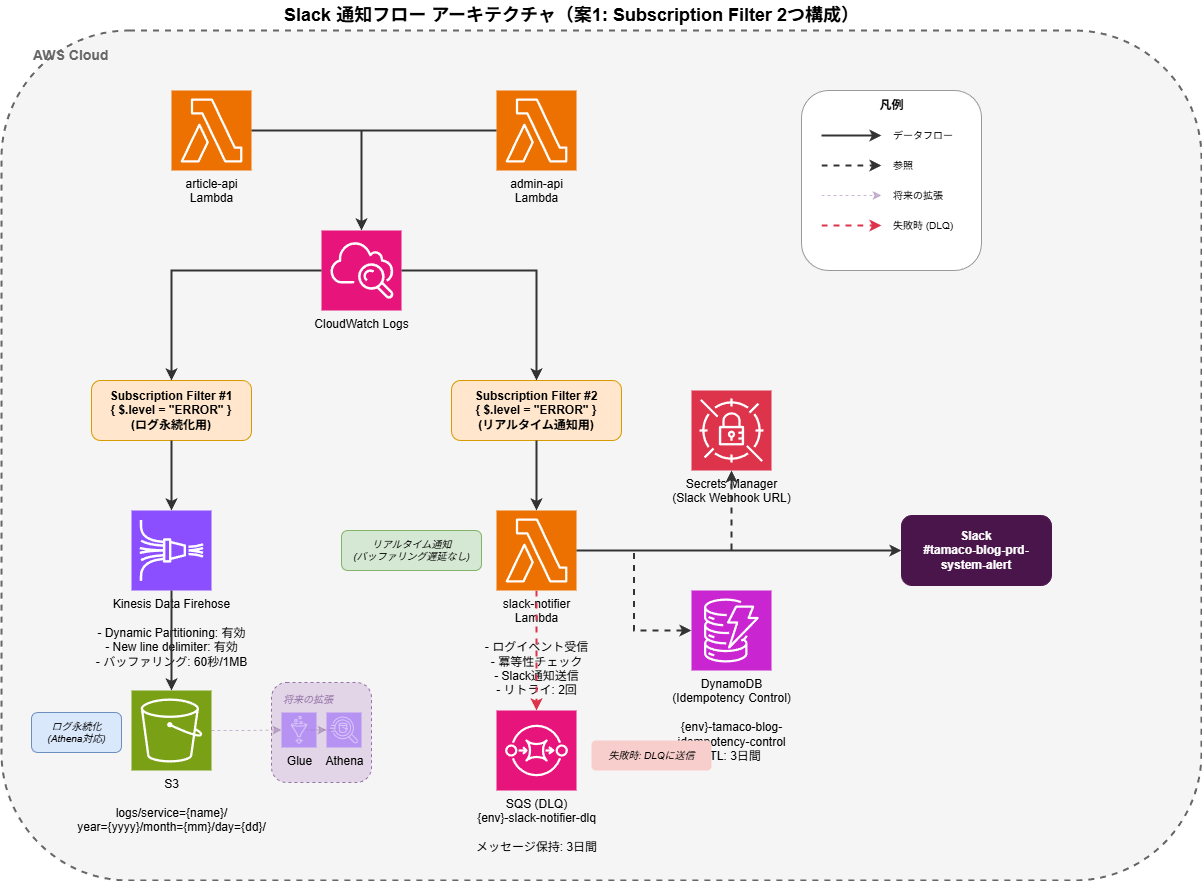
考慮したポイント
ポイント1: 障害発生時のログ調査
よくあるパターンかと思いますが、ログを永続化して Athena 等でクエリ検索できるようにしておくと、あとから原因調査がしやすくなる等の利点があります。
ログを配信する際に、 Kinesis Data Firehose などで動的パーティションさせて、 AWS Glue Crawler (スキーマ自動検出) の構成にしておく等が一般的かと思いますので、この辺りを視野に入れておくことは個人的には重要度は高いと認識しています。
S3 のパーティション構造:
s3://{bucket}/logs/
└── service={service_name}/
└── year={yyyy}/
└── month={mm}/
└── day={dd}/
└── data.gz
なお、個人サービスの場合であったり、比較的小規模なサービスの場合は、この辺りまでは考慮する必要はない認識です。
単一サービスであれば、CloudWatch上でも Logs Insights でログ検索が可能です。
※検索時に使用する構文が少し独特ではありますが、今はAIもあるためあまり悩まずに作成できるかと思います CloudWatch Logs Insights 言語のクエリ構文
ほか、最近の場合はAIを用いてこの辺りの障害の原因分析等を対応するケースもあるかと思いますので、それらのサービスを利用してエラー検知・自分析を行うとなった際にもこの辺りの基盤は必要になる認識です。
ポイント2: Subscription Filter の上限
課題: CloudWatch Logs の Subscription Filter は、1ロググループあたり最大2つまでという制約があります。
Subscription filters per log group Each supported Region: 2 No The number of subscription filters per log group
最終的には以下のような構成にしたのですが、
Subscription Filter 1 → Lambda (Slack通知)
Subscription Filter 2 → Firehose (S3保存)
この場合、Subscription Filter の上限2つを使い切ってしまっているため、将来的な拡張性が失われている状態になっています。
今回はそこまでトラフィック量が多いわけでもない比較的小さなサービスであったため特に問題ないのですが、もし商用向けに展開するとした場合はやや考慮する必要があります。
規模が大きくなってきたりすると、Kinesis Data Streams を利用して、それぞれ適切なリソースに伝搬させる構成をよく見ます。※今回はそこまではやりませんでした
なお、この構成にする場合、特に Lambda 側については以下の点についても考慮しておく必要があります。
-
イベントの順序が保証されない点: エラー通知であり、且つスタックトレースの中に時系列情報も含まれているため順序性は必要なし
-
At-least-once (重複配信) 対策: 今回は DynamoDB を利用して、冪等性検査をしています。用途としてはそれだけなため TTL を利用して3日で削除されるように設定するのが良さそうです。※データが増えすぎてしまうことの弊害 (検索効率低下、セキュリティリスク等) を避ける目的
-
同時実行数制限: Lambdaの同時実行制限はデフォルトでは1000であり、大量のERRORログが短時間で発生した場合はスロットリングが発生しますが、今回はエラー通知のみのためそこまで問題にはならない認識でいます。可用性を上げる場合はSQS等を挟んだり、Lambda の Reserved Concurrency 等を利用するのが良いと思います。
-
失敗時のイベント保存: Subscription Filter から Lambda への非同期呼び出しは自動リトライ(最大2回)がありますが、すべて失敗した場合に備えてDLQ (Dead Letter Queue) で失敗イベントを補足できるようにする必要があります。
ほか、1つの Lambda 内で Slack 通知と S3 保存の両方を行う構成でも要件は満たせるかと思うのですが、アプリケーション視点からすると Slack 通知だけの責務を持たせたかったため、Subscription Filter を2つ使用して責務を分離しました。
ポイント3: コスト (従量課金 vs 固定課金)
ほか、代替案として挙がった構成として、上述した Kinesis Data Streams の利用も検討しました。
この構成のメリットとしては、Subscription Filter を1つに抑えたまま、KDS から複数の送信先 (Lambda, Firehose など) にファンアウトできるため、将来的な拡張性を確保できます。
CloudWatch Logs
└── Subscription Filter (1つのみ)
↓
Kinesis Data Streams (中央ハブ)
├── Consumer 1: Lambda → Slack通知
├── Consumer 2: Firehose → S3保存
├── Consumer 3: Lambda → PagerDuty(将来)
└── Consumer N: 将来の拡張...
が、KDSの場合は従量課金ではなくシャード単位の時間課金が発生してしまうため、上述した通りそこまでトラフィックの多くないシステムでは過剰だと判断し見送りました。
※利用されていない時間帯でも課金が発生してしまうので
ポイント4: 通知遅延の許容
課題: Kinesis Data Firehose のバッファリング機能について
デフォルトでは300秒のバッファリングの間隔があるため、このまま構成した場合、実際にエラーが発生してから通知が行われるまでラグが出てしまいます。が、上述した通り、そこまでトラフィックも多くないサービスのため今回は Kinesis Data Firehose を採用しています。
なお、2023年12月以前までは、このバッファリングで少なくとも60秒は遅延する仕様になっていましたが、ゼロバッファリングをサポートするようになっているようです。ただし、バッファリング間隔を極端に短くしすぎてしまうと、その分出力回数が多くなることからコスト懸念が出てしまうためもしこのゼロバッファリング機能を利用する場合は注意が必要かと思います。
Amazon Kinesis Data Firehose がゼロバッファリングをサポート
ほか、Athena等を利用している場合は dynamic partitioning 等を利用するケースもあるかと思いますが、こちらを有効にしている場合はゼロバッファリング機能は利用できないようですので注意が必要です。
Buffer data for dynamic partitioning
Zero buffering feature is not available for dynamic partitioning.
その他検討したこと
- 通知サービスに AWS Chatbot もあるのですが、通知フォーマットに柔軟性を持たせられない点や、メトリクス情報のみでエラー詳細は含まれない点等もあるため、別途 Slack通知用のLambdaを構成を選択しています。※なお、Datadog や New Relic 等のSaasを利用している場合はそちらを利用するのが一般的かと思います。
まとめ
AWS Lambda のエラー通知を Slack に送る構成を設計する際に考慮したポイントを解説しました。
| ポイント | 内容 | 対応 |
|---|---|---|
| ログ永続化 | CloudWatch の保持期間は短い | S3 に自動保存 |
| 将来の拡張性 | Athena / Bedrock 連携 | 拡張しやすい構成を選択 |
| Subscription Filter 上限 | 1ロググループあたり最大2つ | 2つ使用(通知 + 永続化) |
| コスト | 固定課金を避けたい | 完全従量課金のサービスのみで構成 |
| 通知遅延 | リアルタイム通知が望ましい | Lambda 直接トリガーで数秒以内 |
この構成により、低コスト・拡張性・ログ永続化を両立しています。