[OpenTelemetry 検証4] Prometheus UI を使用してメトリクスを見てみる
はじめに
[OpenTelemetry検証3] Grafana × Loki を使用してログを見てみる の続きです。
なお、Prometheus UI はクエリの動作確認や素早いデバッグに適していますが、グラフの可視化やダッシュボードの構築には Grafana を使う方が適しています。
今回はあくまでも検証ということで、いろいろ見ていけたらと思っています。
内容
早速見ていきます。
今回は Prometheus UI を使ってメトリクスの情報を見てみたいと思います。
まずは http://localhost:9090 にアクセスします。最初は以下のような画面になっているかと思います。
ここからは、 PromQL を使って検証していきたいと思います。
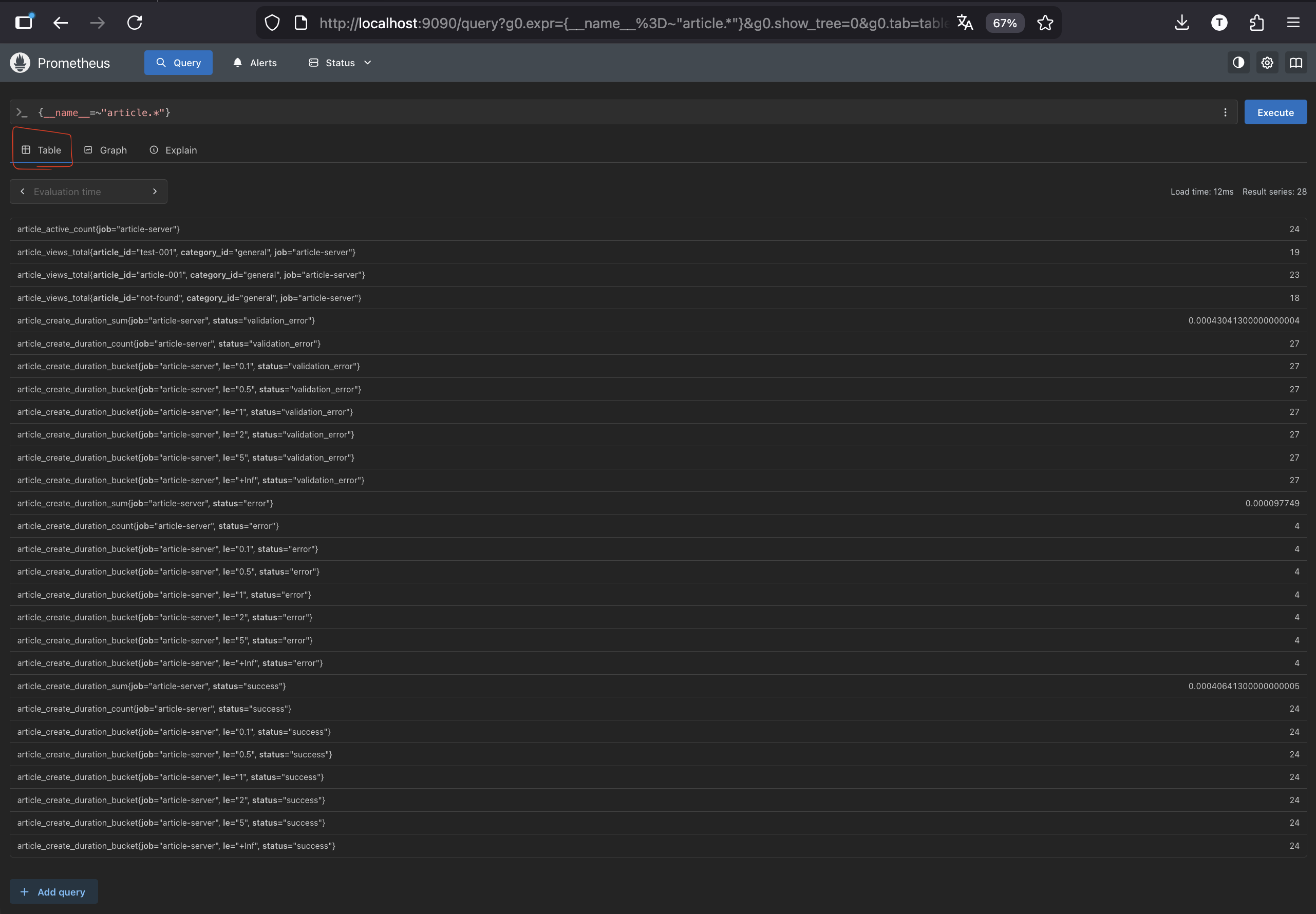
まずは、{__name__=~"article.*"} で、article で始まる名前のメトリクスをすべて取得してみます。
本来は個別で検索するのですが、メトリクス名などがわからない場合にこれで確認できたりします。
メトリクス名がわかったので、試しに article_views_total で検索してみます。※結果が消失しないように私はよくタブ複製で別タブにして検索することが多いです
ちなみに、 article_views_total は GET /articles/{id} が呼ばれるたびにカウントアップされる 累計閲覧数を意味します。
すると以下のような結果が得られました。
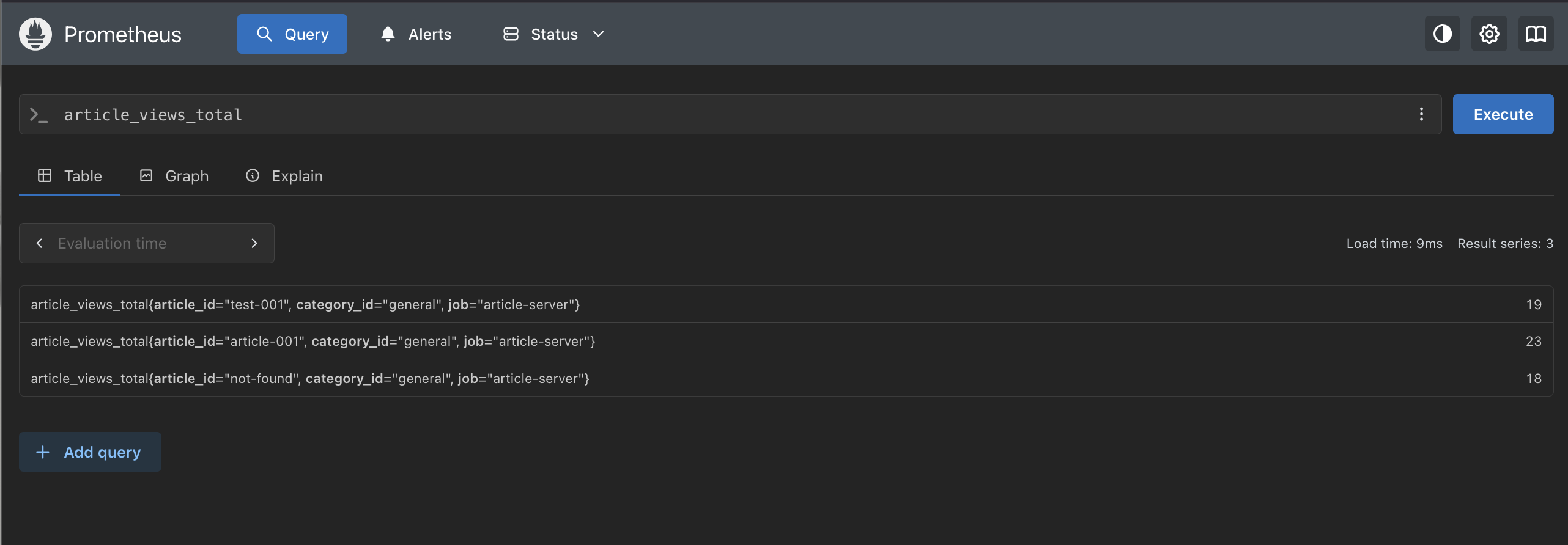
| article_id | 閲覧数 | 意味 |
|---|---|---|
article-001 | 23 | 最も多くアクセスされた記事 |
test-001 | 19 | 2 番目に多い記事 |
not-found | 18 | 存在しない記事へのアクセス |
この結果から、article_id=article-001が最も多く GETリクエストされている (つまり閲覧されている) ということがわかります。
これを応用して、特定の記事の累計閲覧数を取得してみます。
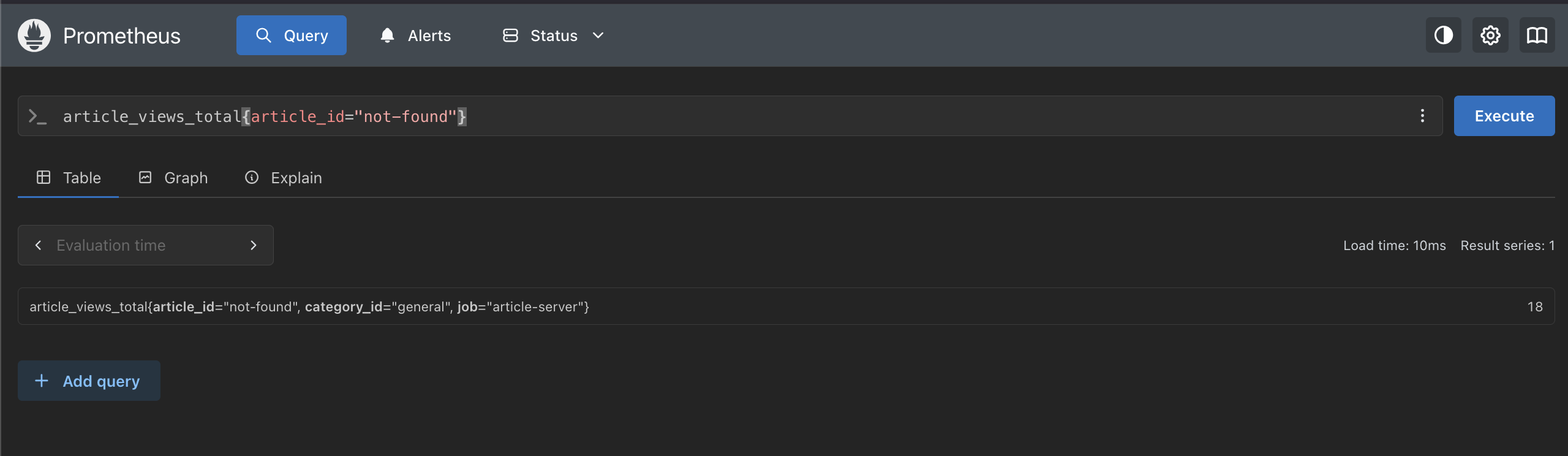
以下のように、{} の中にラベルと値を指定することで、特定の条件で絞り込むことができます。
article_views_total{article_id="not-found"}
よく使う汎用的なクエリ
ステータス別の集計
成功・エラー・バリデーションエラーの件数比較して、全体像をステータス別に俯瞰する。
sum by(status) (article_create_duration_count)
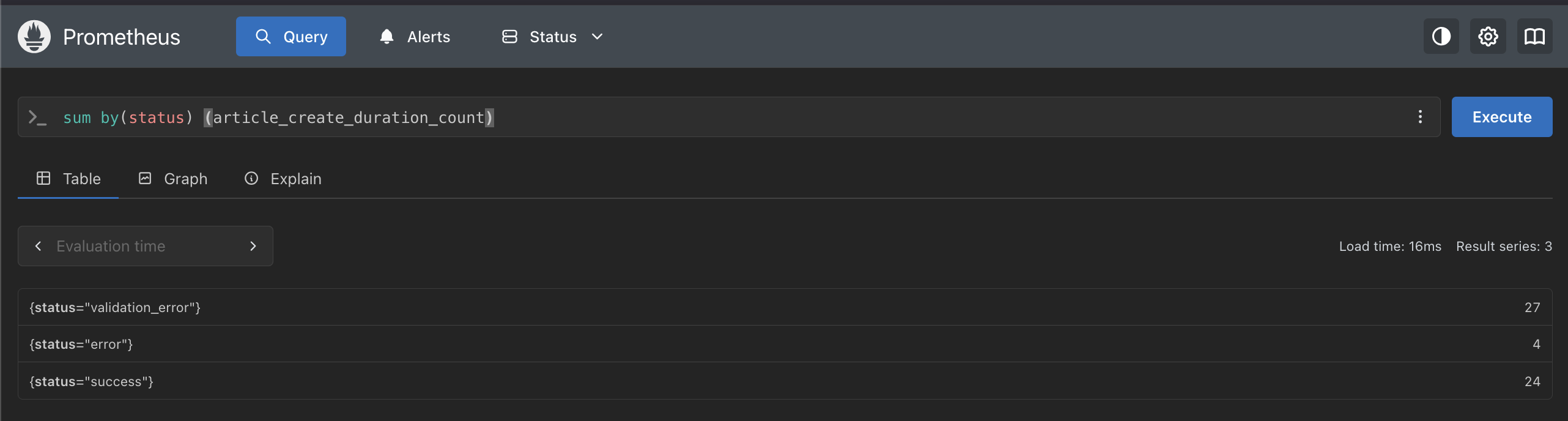
| status | 件数 | 意味 |
|---|---|---|
validation_error | 27 | タイトルなしなど入力ミスのリクエスト |
success | 24 | 正常に作成できたリクエスト |
error | 4 | DB エラーが発生したリクエスト |
エラーのみに絞って件数を取得する。
article_create_duration_count{status="error"}
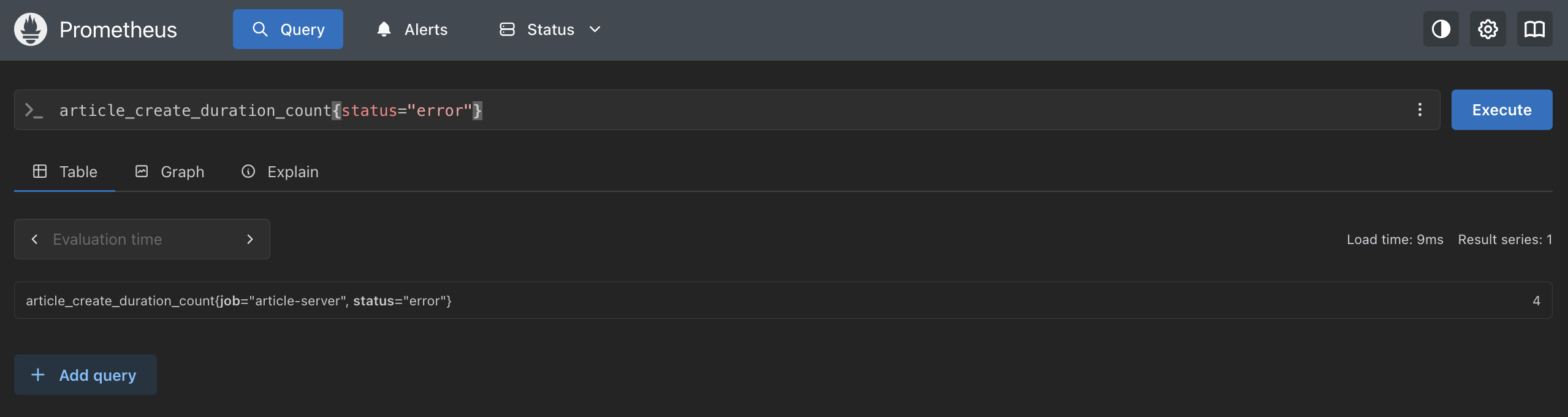
DB エラーが発生した記事作成リクエストだけを絞り込んだ結果。
HTTP リクエスト系
直近5分間の1秒あたりのリクエストレート
rate(article_views_total[5m])
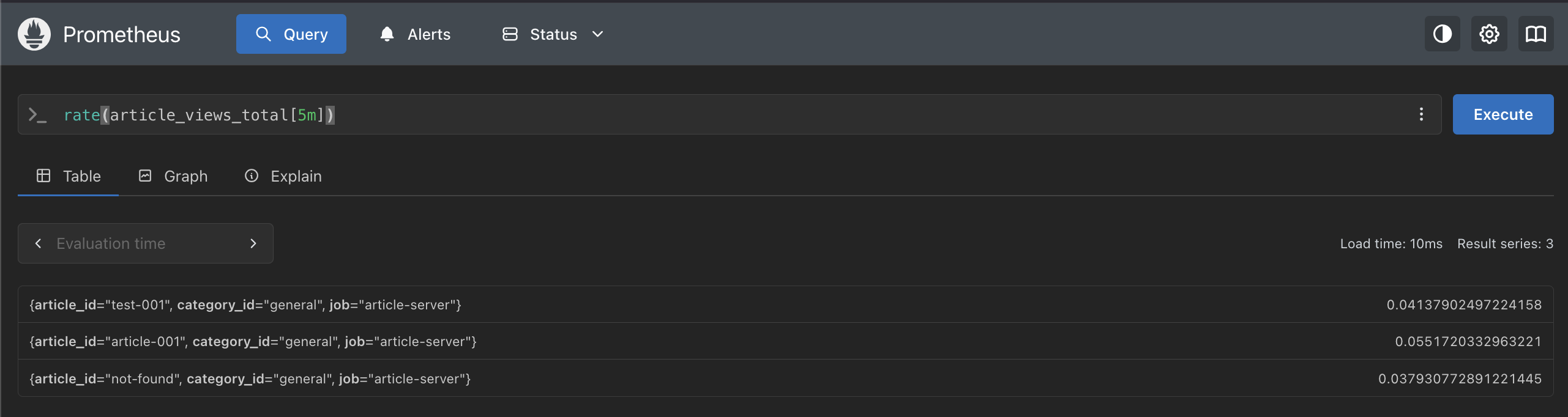
| article_id | rate | 約何秒に 1 リクエスト |
|---|---|---|
article-001 | 0.0552 | 約 18 秒に 1 回 |
test-001 | 0.0414 | 約 24 秒に 1 回 |
not-found | 0.0380 | 約 26 秒に 1 回 |
上記の結果からは、トラフィックの偏りがわかります。
例えば、article-001 が最もアクセスが多く、not-found が最も少ないことがわかるため、記事ごとの人気度をリアルタイムで把握できます。
ほか、サービス全体のスループットもこの結果からわかります。
sum(rate(article_views_total[5m])) で3つのリクエストを合計すると、0.135 リクエスト/秒 = 約 7 秒に 1 リクエストがサービス全体に来ていることがわかります。
article_views_total は起動からの累計件数 (増え続ける) ですが、rate(article_views_total[5m]) を使用すると、直近 5 分の増加速度 (現在の負荷) を求めることが可能になります。
レイテンシ系 (Histogram)
記事作成の平均処理時間 ※ 処理時間の合計 ÷ リクエスト数 = 平均処理時間
rate(article_create_duration_sum[5m]) / rate(article_create_duration_count[5m])
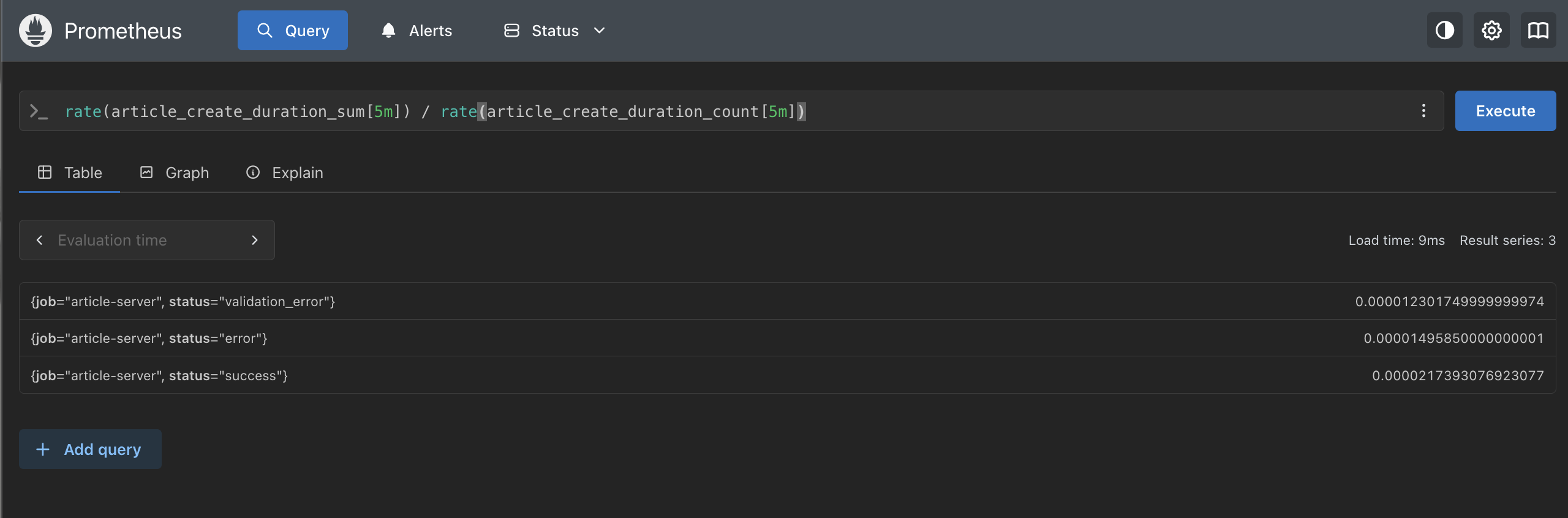
| status | 平均処理時間 | ミリ秒換算 |
|---|---|---|
success | 0.000000217s | 約 0.000217ms |
error | 0.000000150s | 約 0.000150ms |
validation_error | 0.000000123s | 約 0.000123ms |
記事作成のリクエストを対象にした計測です。
今回はDB操作などはmock的に実行しているため、全て高速な処理になっていてわかりづらいですが、
特に validation_error などは、入力値の検証などで不正なリクエストと判断した場合は DBアクセスする前に弾くため、ほかのステータスよりも早い。
一方 success に関しては、最初から最後まで処理を実施するため、他と比べて時間がかかる、などの分析ができるかと思います。
95, 99パーセンタイルレイテンシ
現在のアプリケーションは mock で実装しているため、意図的に遅延させるように以下のように修正する。
diff --git a/otel/article_server/internal/usecase/create.go b/otel/article_server/internal/usecase/create.go
index ac96556..5800c3d 100644
--- a/otel/article_server/internal/usecase/create.go
+++ b/otel/article_server/internal/usecase/create.go
@@ -3,6 +3,7 @@ package usecase
import (
"context"
"fmt"
+ "math/rand"
"time"
"github.com/tamaco489/otel_sample/otel/article_server/internal/entity"
@@ -55,6 +56,11 @@ func (u *articleUsecase) Create(ctx context.Context, input *CreateArticleInput)
// イベント: 作成開始
span.AddEvent("create_started")
+ // NOTE: 20% の確率で 200ms〜1秒の遅延を発生させる
+ if rand.Float64() < 0.2 {
+ time.Sleep(time.Duration(200+rand.Intn(800)) * time.Millisecond)
+ }
+
// リポジトリで作成
article := &entity.Article{
Title: input.Title,
❯ git diff otel/article_server/internal/usecase/get_by_id.go
diff --git a/otel/article_server/internal/usecase/get_by_id.go b/otel/article_server/internal/usecase/get_by_id.go
index adb186c..65ee988 100644
--- a/otel/article_server/internal/usecase/get_by_id.go
+++ b/otel/article_server/internal/usecase/get_by_id.go
@@ -2,6 +2,8 @@ package usecase
import (
"context"
+ "math/rand"
+ "time"
"go.opentelemetry.io/otel/attribute"
"go.opentelemetry.io/otel/codes"
@@ -26,6 +28,11 @@ func (u *articleUsecase) GetByID(ctx context.Context, id string) (*entity.Articl
attribute.String("article.id", id),
)
+ // NOTE: 20% の確率で 200ms〜1秒の遅延を発生させる
+ if rand.Float64() < 0.2 {
+ time.Sleep(time.Duration(200+rand.Intn(800)) * time.Millisecond)
+ }
+
// リポジトリ呼び出し
article, err := u.repo.FindByID(ctx, id)
if err != nil {
histogram_quantile(0.95, rate(article_create_duration_bucket[5m]))
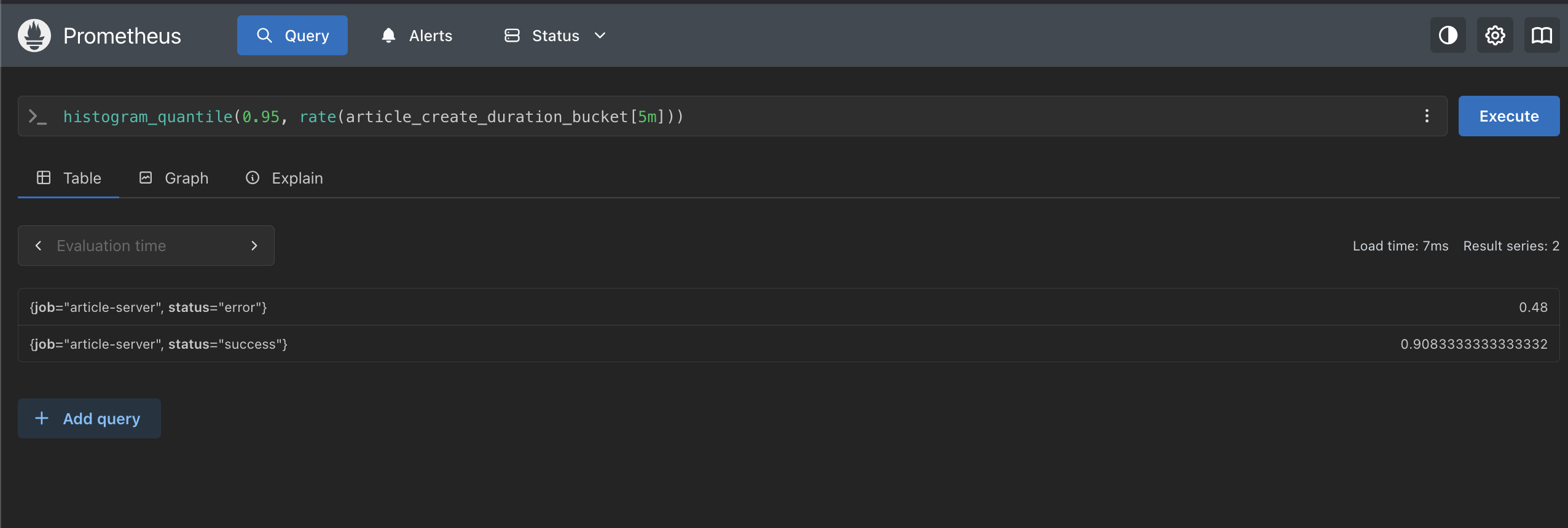
| status | 95 パーセンタイル | 意味 |
|---|---|---|
success | 0.908s | リクエストの 95% が 0.908 秒以内に完了 |
error | 0.48s | リクエストの 95% が 0.48 秒以内に完了 |
histogram_quantile(0.99, rate(article_create_duration_bucket[5m]))
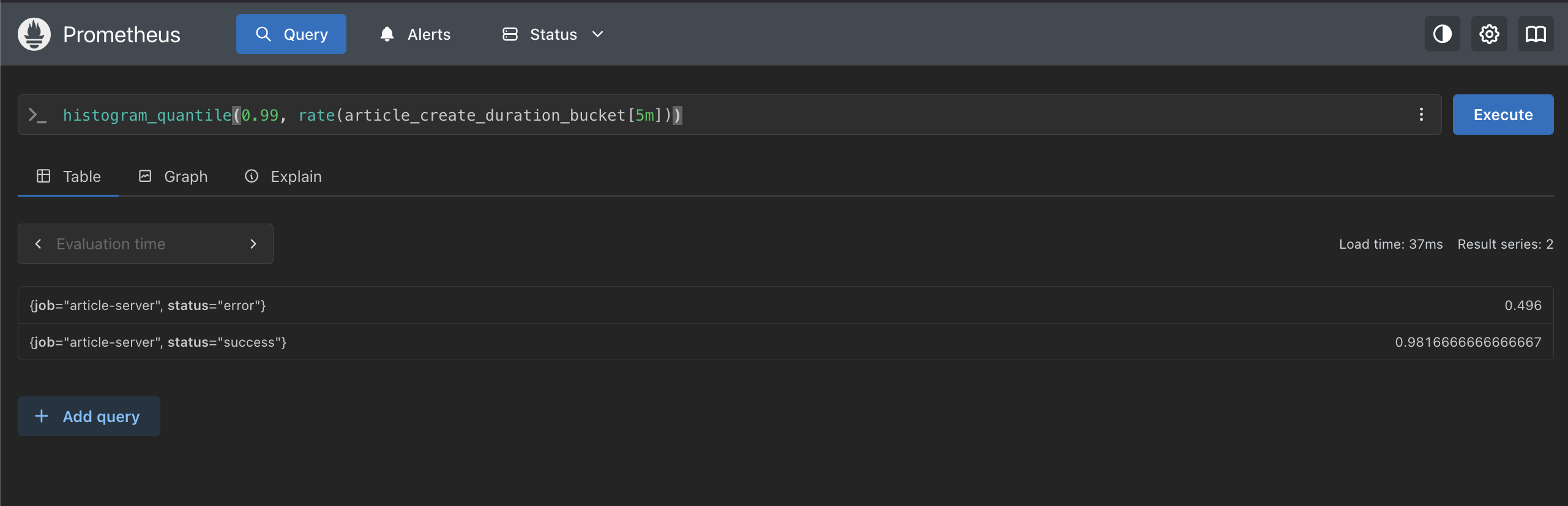
| status | 99 パーセンタイル | 意味 |
|---|---|---|
success | 0.982s | リクエストの 99% が 0.982 秒以内に完了 |
error | 0.496s | リクエストの 99% が 0.496 秒以内に完了 |
おわりに
今回は Prometheus UI を使用してメトリクスを見ていきました。他にも様々な機能があるため興味があれば調べてみるといいでしょう。
- Counter / Histogram / Gauge それぞれの特性と使い分け
- rate() で現在の負荷をリアルタイムに把握する方法
- histogram_quantile() で p95 / p99 のレイテンシを計算する方法
- sum by(status) でステータス別に集計する方法
次回は Grafana を使って同じようにメトリクス周りを見ていきたいと思います。