[OpenTelemetry 検証6] Grafana ダッシュボードを作成・編集してみる
はじめに
[OpenTelemetry 検証5] Grafana を使ってメトリクスを見てみる の続きです。
前回は Grafana Explore を使って Prometheus のメトリクスをグラフで可視化して遊んでみましたが、今回はそれらを応用してダッシュボードを作成し、複数のパネルを 1 画面にまとめて監視できる状態にしていきたいと思います。
また、Grafana はダッシュボードを UI から手動で作成するだけでなく、JSON ファイルをあらかじめ配置しておくことで起動時に自動読み込みする仕組み (プロビジョニング) をサポートしています。
本番運用中は基本的には手動で作成、変更することが多いのですが、今回はある程度再現性を持たせながら実装をしたいので、このプロビジョニングを利用しながら実装していきたいと思います。
事前設定
ダッシュボードの設定に関しては以下に配置しています。
なお最初からここに配置してダッシュボードを作成するとかなり効率が悪いので、ある程度UI上で操作して内容が固まり次第ここに配置する順番が良いと思います。
❯ tree ./_docker/grafana/
./_docker/grafana/
├── grafana.ini
├── provisioning
│ ├── dashboards
│ │ ├── article-server.json // ダッシュボードの詳細な定義
│ │ └── dashboards.yaml // Grafana 起動時に JSON ファイルから自動的にダッシュボードを読み込む設定
│ └── datasources
│ └── datasources.yaml
└── setup.sh
4 directories, 5 files
以下設定内容の詳細です
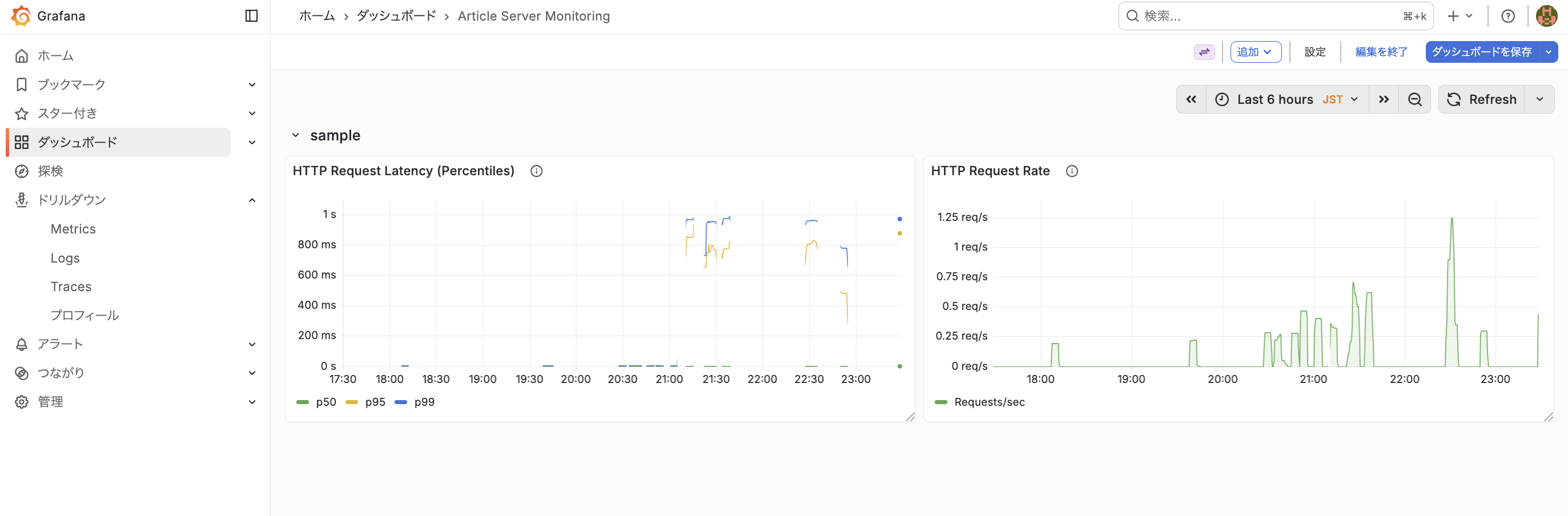
こちらを設定して Grafana を起動すると以下のようなダッシュボードになります。
詳細
全て解説すると長くなるので、1つ目のダッシュボード、「HTTP Request Latency (Percentiles)」についてのみ触れます。
こちらは HTTP レイテンシ・リクエストレート・エラー率などを監視する用途で設定しており、p50 / p95 / p99 の 3 本の線を 1 つのグラフに重ねて表示するような設定にしています。
histogram_quantile(0.5, sum(rate(http_server_request_duration_seconds_bucket[5m])) by (le))
histogram_quantile(0.95, sum(rate(http_server_request_duration_seconds_bucket[5m])) by (le))
histogram_quantile(0.99, sum(rate(http_server_request_duration_seconds_bucket[5m])) by (le))
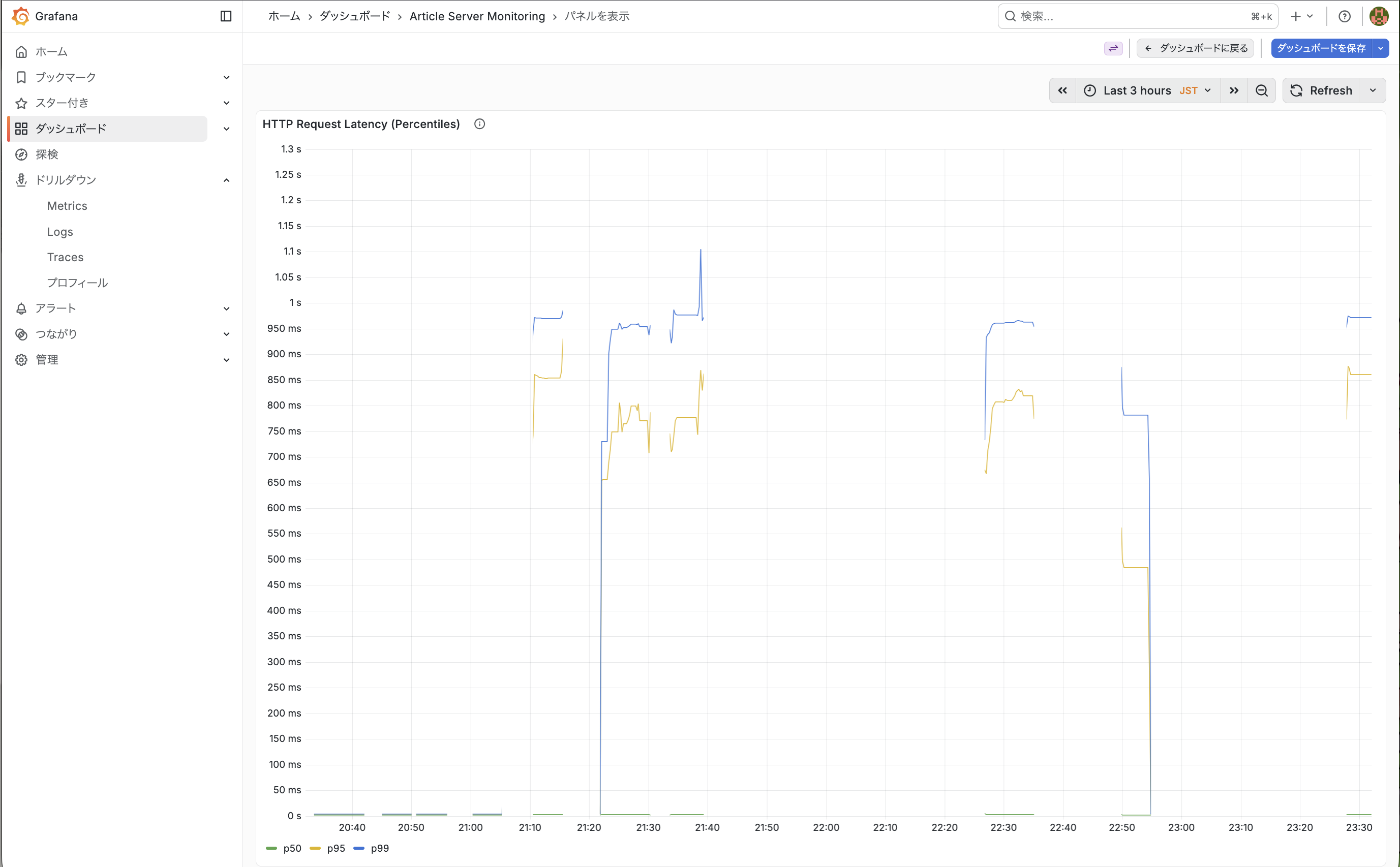
このグラフから以下が読み取れるかと思います。
- p50 (緑) がほぼ 0ms に張り付いている
- 全リクエストの 50%以上は数ミリ秒以内に完了していることを表しています。
- 遅延ロジック(負荷の高い処理)が発動しなかった大多数のリクエストが p50 を引き下げていることがわかります。
- p95 / p99 が 700ms〜1.1s に跳ね上がっている
- 上位 5% (p95), または1% (p99) リクエストで 1 秒前後の遅延が発生していることを表しています。
- これは負荷の高い処理を再現するために usecase に仕込んだ「20%の確率で 200ms〜1000ms の遅延を発生させる」ロジックが機能している結果になります。
- p50 と p95/p99 の差が極端に大きい (二極化している)
- 通常の健全なシステムでは 3 本の線が近い値で推移することが多いかと思いますが、このグラフでは p50 ≈ 0ms に対して p99 ≈ 1s と分布が二極化していることがわかります。※ ≈ (ニアリーイコール)
- これは「速いリクエスト」と「遅いリクエスト」が混在していることを意味するため、本番環境でこの形が出た場合、特定条件下でのみ遅くなるバグのようなものが潜んでいることがわかるかと思います。
まとめると、このグラフは 「大多数は高速だが、一部が極端に遅い」という偏った分布になっており、仮に p50 だけを監視していると問題を見逃すケースがあることを教えてくれるようなグラフになっています。
グラフを編集してみる
グラフの編集は簡単です。以下の画面から編集できます。
入力フォームに先ほどの promql をそれぞれ設定するようなイメージになります。
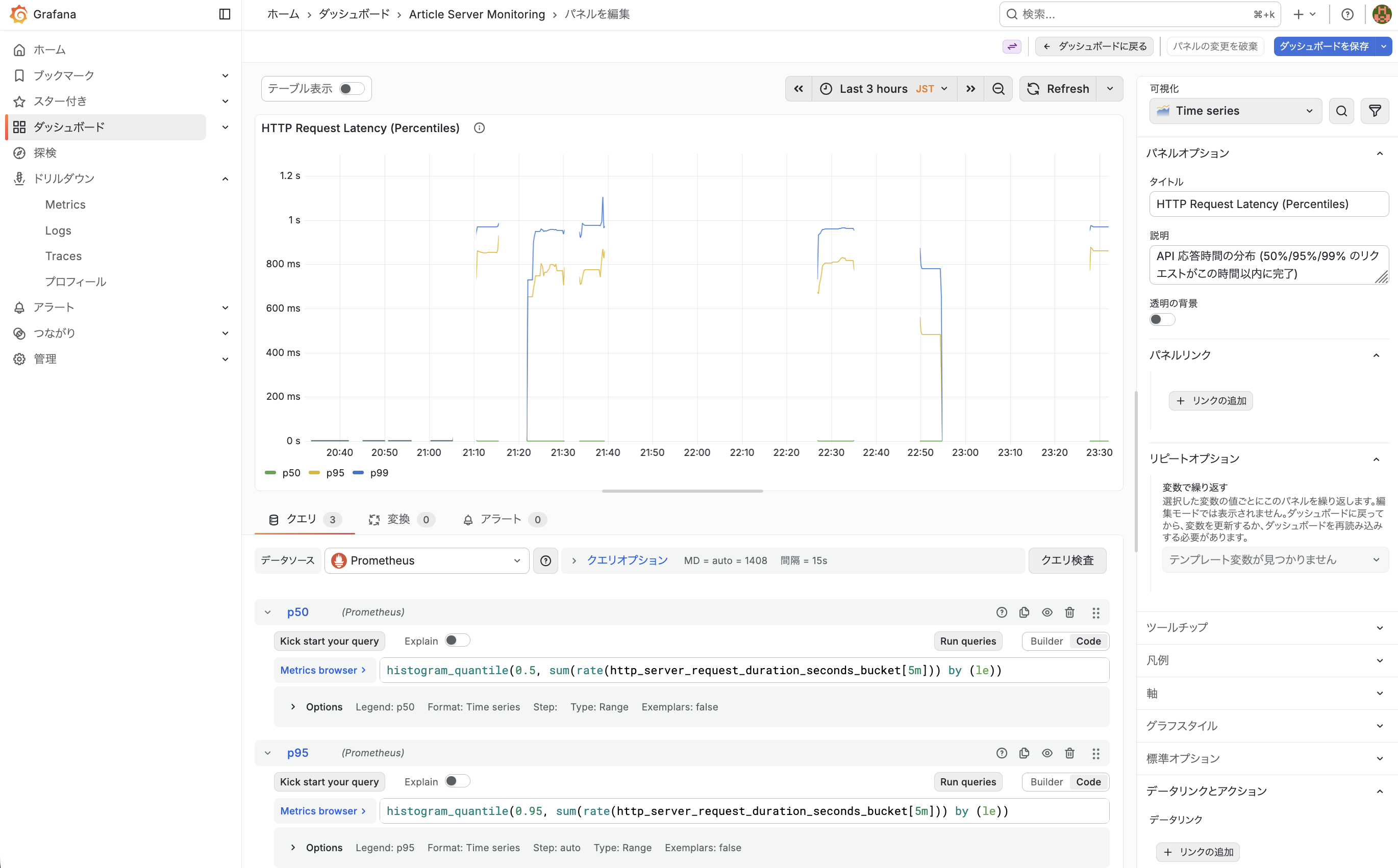
なお、現在のダッシュボードは、グラフからトレースなどの情報にアクセスできるような状態になっていないため、その設定をやってみたいと思います。
URLには以下のように設定します。
/explore?left={"datasource":"tempo","queries":[{"refId":"A","queryType":"traceql","query":"{}"}],"range":{"from":"${__from}","to":"${__to}"}}
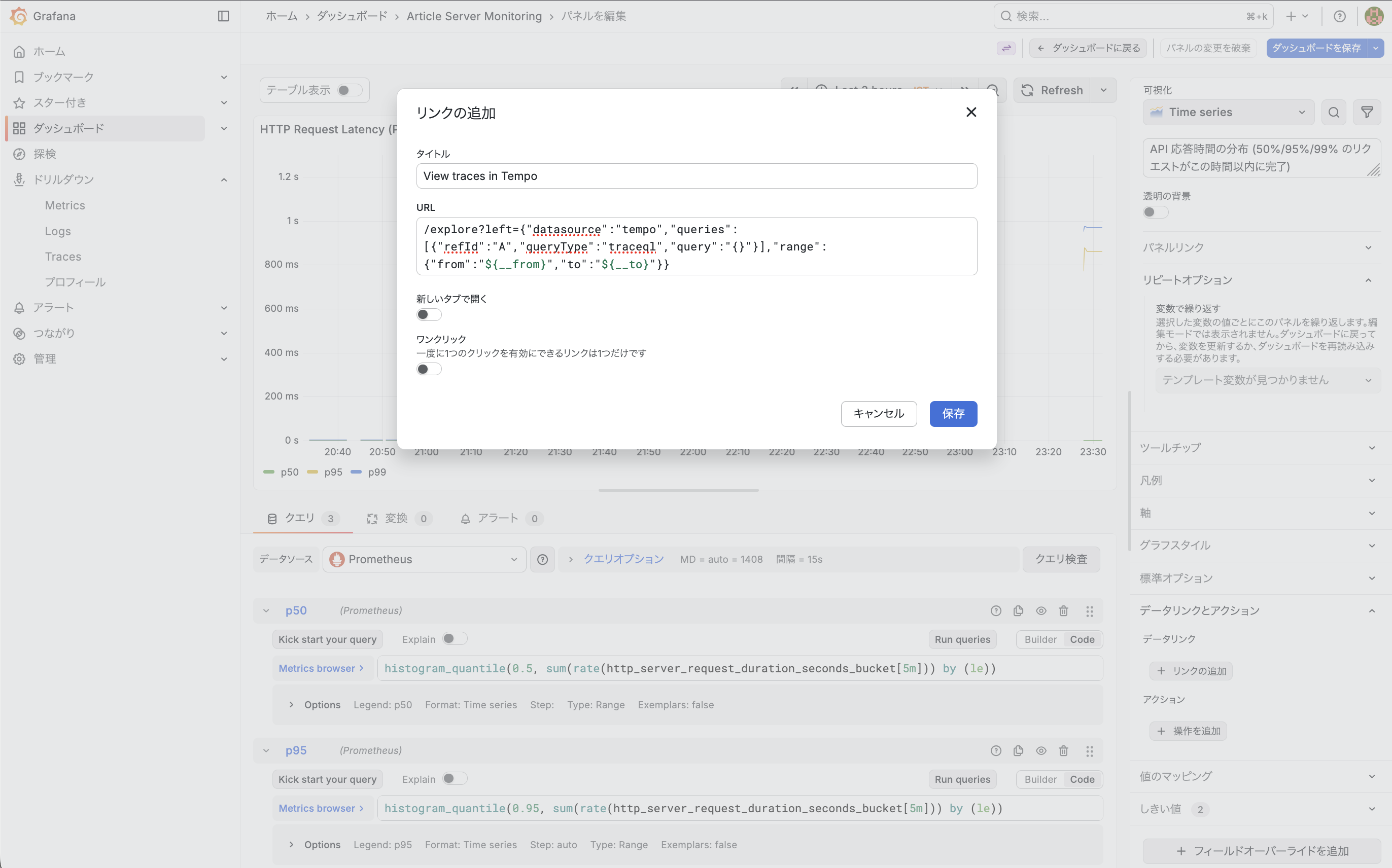
備考:
- ダッシュボードをプロビジョンモードで設定している場合は UIからの保存はできないため、ここで設定内容のJSONが出力されるのでそれをコピーし、
article-server.jsonに設定を反映させる必要があります。 dashboards.yamlにupdateIntervalSeconds: 10を設定しておくと、コンテナの再起動なども不要で json を変更して10秒後にブラウザをリロードすると設定が反映されているかと思います。
設定が反映されると以下のように、ダッシュボードから Tempo のトレース画面に遷移することができます。
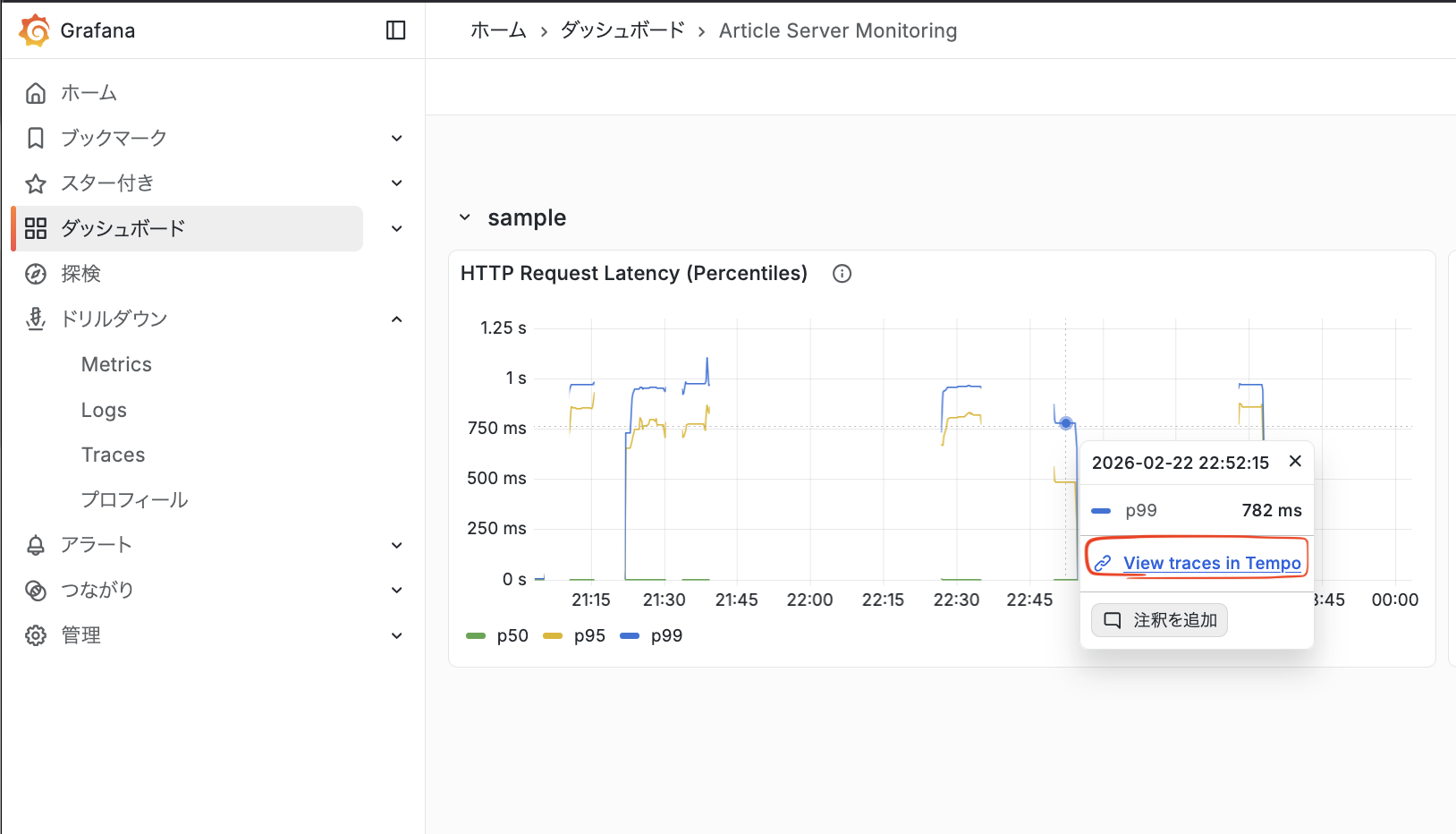
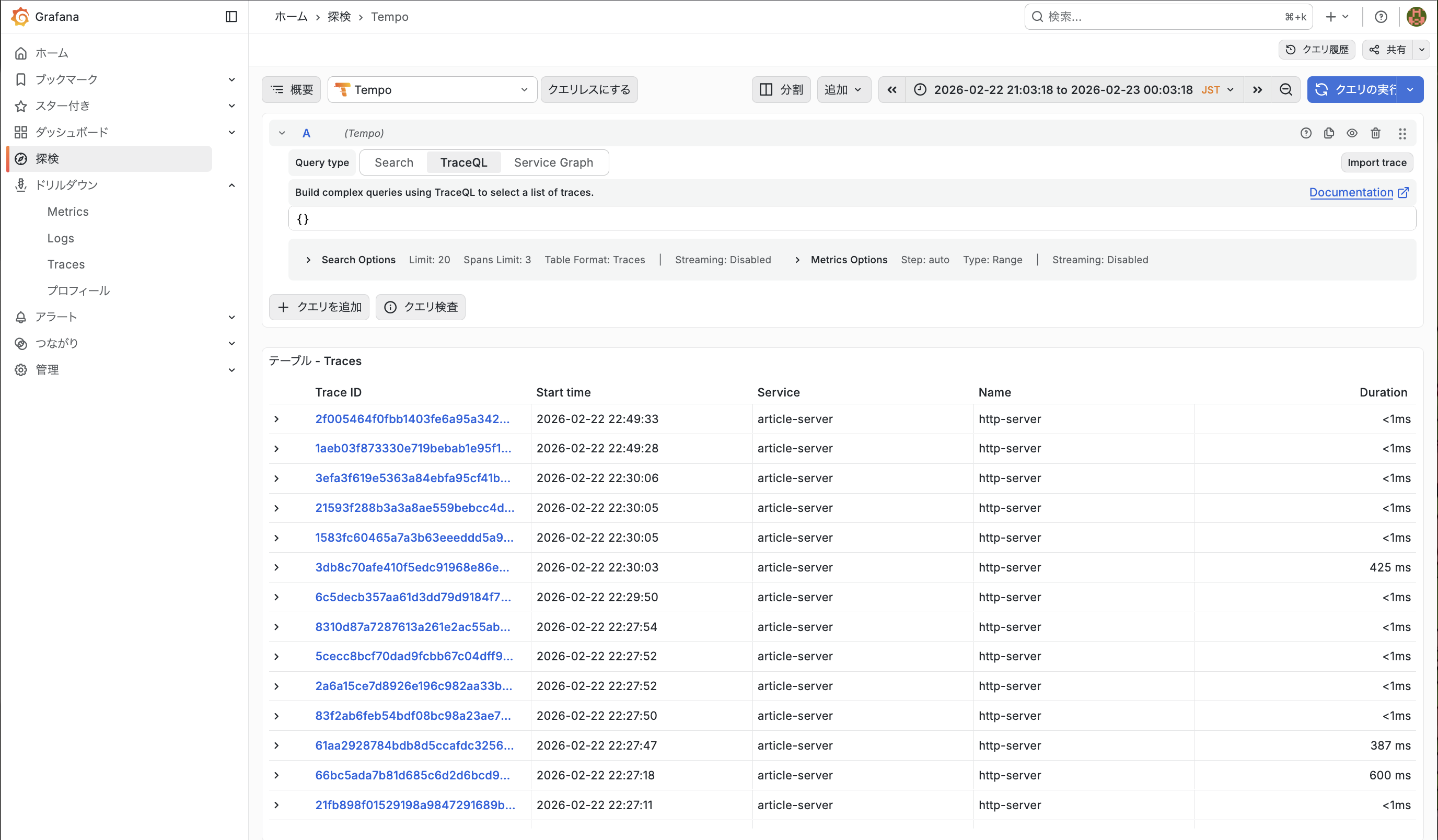
おわりに
今回はプロビジョニング機能を使って Grafana ダッシュボードを自動読み込みし、HTTP レイテンシとリクエストレートを 1 画面で確認できる状態を作成してみました。
また、データリンクを設定することでメトリクスのグラフから Tempo のトレースの画面へ直接遷移できるようにする設定も行いました。ダッシュボードが洗練されていくと運用もかなり楽になるため、非常に強力な機能であると認識しました。
なお、ダッシュボードは一度作成して終わりではありません。運用を続けていくと色々な気づきが出てくるため、日々変化する事象にどれだけ気づいてダッシュボードに反映できるかが重要です。
次回はアプリケーション側を少し改修したいと思います。
具体的には、PostgreSQL のドライバである pgx にカスタムトレーサーを実装し、SQL クエリの実行を span として自動記録するような構成にしてみたいと思います。